Why Software Engineers Are the Best AI Engineers
A look at what the market is actually hiring for, and a friendly debate between two camps that both think they own the title.
The AI Engineer Identity Debate
Ask ten people what an "AI Engineer" does and you'll get ten different answers. One will describe someone fine-tuning transformer models. Another will describe someone wiring up a LangChain agent over a vector database. A third will describe someone running Kubernetes clusters for inference workloads.
They're all right, in some shape or form, and that's our point for debate today. "AI Engineer" has become a container word, and the industry has yet to settle on what's inside it. So before we argue about who owns the role, let's pull it apart.
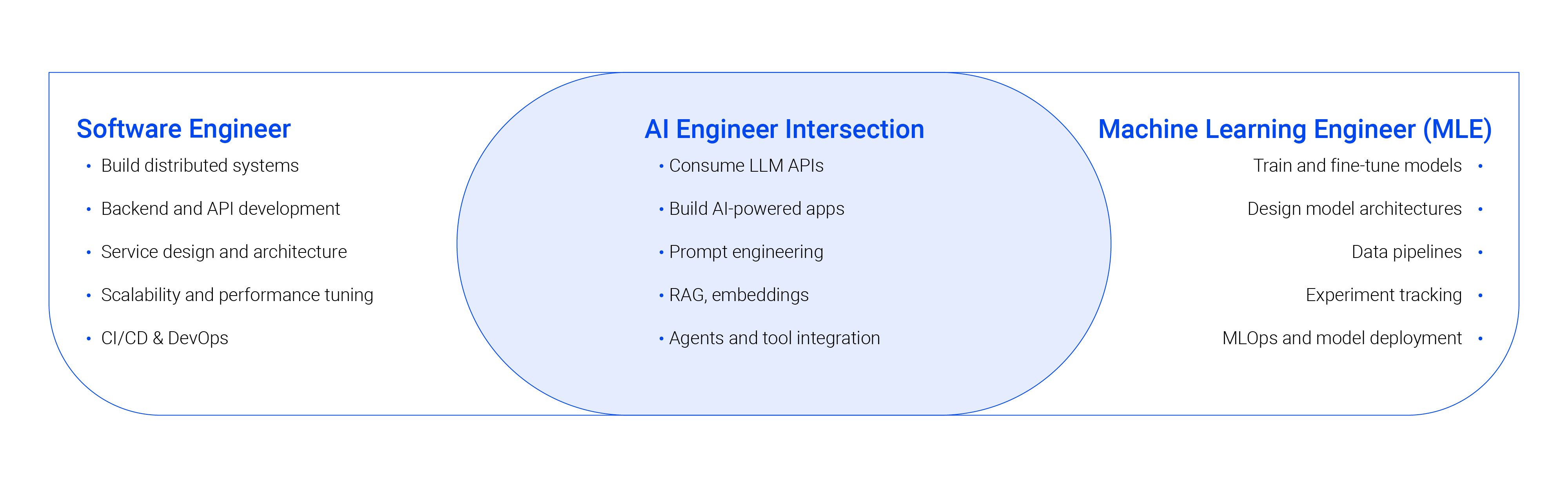
Three “Flavors” of AI Engineer
In practice, the AI Engineer title is unfolding into three distinct sub-roles. They share a vocabulary, but their day-to-day work is different.
The MLE-flavored AI Engineer. This is the engineer whose roots are found in machine learning. They live in the world of embeddings, recommender systems, NLP, and model behavior. They improve RAG systems by tuning chunking, and re-ranking strategies, they fine-tune LLMs when the use case justifies it, and they treat prompt engineering as a first-class research discipline. They care about model quality the way a chef cares about ingredients.
The SWE-flavored AI Engineer. This is the engineer coming from backend, and increasingly frontend development. They use embedding APIs and chat models as components, not as research artifacts. They connect tools with frameworks like LangChain and LangGraph, ship them in Docker containers, and worry about latency, cost, observability, and long-term maintenance. They rarely train a model from scratch (though they understand how one works under the hood), instead they orchestrate them by wrapping them in agents capable of performing autonomous actions to solve problems.
The LLMOps-flavored Engineer. This is the engineer closest to the infrastructure, they deploy and monitor, they deploy and monitor LLM-backed services, wire up observability stacks such as Langfuse, Phoenix, OpenWebUI, and DeepEval, and live inside Kubernetes manifests. Their concerns extend well beyond classical DevOps: they manage prompt versioning, model routing and fallback strategies, token budget enforcement, evaluation pipelines that run continuously in production, and the telemetry needed to detect quality drift before customers do. Where a traditional DevOps engineer keeps a deterministic service alive, an LLMOps engineer keeps a probabilistic one honest — and that distinction is what makes this flavor distinct enough to deserve its own label.
These are not rigid identities since a strong SWE can comfortably absorb most Ops-flavored responsibilities. A strong MLE can step into SWE-flavored work, though the reverse transition is slower. But the point of the taxonomy it's to ask a useful question: which role is the market actually buying?
Where the Lines Blur
The lines between these flavors are increasingly blurring, and much of what looks like MLE territory is being absorbed by the SWE side of the table. Evaluation is, at its core, a testing problem: define expected behavior, exercise the system against it, surface regressions when it drifts. Observability is a logging and tracing problem dressed up in new clothes. Guardrails are input validation and fallback logic. Confidence thresholds and progressive rollouts are feature-flagging and gradual deployment — things SWEs have been shipping in production for two decades. None of these concepts are foreign to a senior Software Engineer; they are simply being applied to a probabilistic component instead of a deterministic one. What the SWE-flavored AI Engineer brings is a hardened intuition for how to operationalize these concerns at scale, with proper CI integration, alerting, and rollback paths — turning what the MLE describes as a research discipline into something that ships on a Tuesday and keeps shipping every Tuesday after that.
The MLE Perspective: "We Built the Engine"
An MLE reading this article would push back, and fairly so. Every system the SWE-flavored AI Engineer builds runs on top of decisions an MLE made. Embedding choice, chunking strategy, evaluation methodology and guardrail design. Confidence thresholds for human handoff. Pick any AI Engineer job description and you'll find an MLE concern sneaking in, usually under a phrase like "experience designing evaluation frameworks for LLM output quality" or "comfort with human-in-the-loop to autonomous rollout patterns."
The MLE's argument is that orchestration without measurement is theater. You can string LangChain calls together all day, but if you can't reason about whether the output is actually correct, you've shipped a liability disguised as a feature. The roles that look like SWE work on the surface, the MLE says, quickly become MLE work the moment they touch reality.
The SWE Perspective: "We Ship a working car"
The SWE's counter-argument is that the substrate is now commoditized. You don't need to train an embedding model in 2026, you call one. You don't need to host your own LLM, you hit an API. The hard problems have moved up the stack: how do you make a multi-agent workflow reliable across a thousand customer accounts? How do you keep token costs under control while latency stays inside an SLA? How do you ship a feature that depends on a probabilistic system to a deterministic enterprise customer with a compliance team?
These are software engineering problems. They demand strong system design, an instinct for trade-offs, comfort with distributed job processing, and the discipline of testing and observability. They demand someone who can translate "we want fewer support tickets" into a working production system: a containerized service that calls an LLM, retries gracefully when the provider hiccups, falls back to a cheaper model or a deterministic path under load, emits structured traces to whatever observability layer the company has standardized on, runs continuous evaluations against a golden dataset, and ships behind a feature flag so it can be rolled back in seconds. Every one of those decisions — retry policy, fallback strategy, tracing schema, eval cadence, rollout mechanism — is a software engineering decision before it is an AI decision. The model is one component in a system that has to behave well even when the model misbehaves.
This is exactly where the two perspectives meet. The MLE is right that evaluation and measurement matter; the SWE is right that the place those concerns get exercised is in production code, on a deployment pipeline, behind a feature flag. The disciplines overlap, but the gravitational center of the AI Engineer role has moved from model creation to system construction — and the deals back that up.
What the Market Is Actually Asking For
Looking across a recent slice of AI Engineer requisitions, spanning a wide range of industries, company sizes, and use cases — a clear pattern emerges.
The overwhelming majority of these roles are SWE-flavored. Roughly seven in ten of the AI Engineer requisitions reviewed lead with Software Engineering fundamentals: Python proficiency, API and microservice design, containerization, version control, and integration with LLM provider APIs such as Anthropic, OpenAI, and Amazon Bedrock. The AI part of the role is most often phrased as integrating generative models into production systems, orchestrating agentic workflows, or building MCP servers and tool integrations, not as training or researching models.
The recurring skill stacks across these requisitions tell the same story: One asks for an engineer who can architect an AI-native software development lifecycle, with contract-first APIs, schema-driven workflows, and AI-assisted CI/CD gates. Another asks for a hands-on technical lead fluent in Python, TypeScript, modern web frameworks, and managed LLM services (Bedrock, Azure OpenAI, or similar) to ship production AI tooling end-to-end. This other one seeks for an engineer comfortable building agentic workflows in Python with Docker, message queues, and MCP-based integrations on top of an existing data backbone. One more looks for strong backend fundamentals, cloud storage, API design, prompt engineering, RAG, and evaluation frameworks, to convert messy unstructured inputs into reliable structured outputs.
Different industries, different use cases, but with very similar technical requirements.
Across these, the unifying language shifts away from "model architecture" and gravitates towards "production-grade reliability," "evaluation frameworks," "human-in-the-loop rollout," "cost and latency trade-offs," and "system design." That is the vocabulary of a strong Software Engineer who happens to ship AI features. And it matters because it signals that the field has matured past the proof-of-concept phase.
The novelty of AI is no longer the headline; what employers actually need is someone who can take a probabilistic component and embed it inside a deterministic system without breaking the contract that system has with its users. That requires the same discipline that ships any production service: clean interfaces, graceful degradation, instrumentation, and the judgment to know when not to use AI at all. A smaller cluster of roles includes MLE: NLP pipelines, classical ML tooling (scikit-learn, PyTorch), hyperparameter tuning, vector DB internals. Another small cluster leans Ops, typically around low-code platforms like Copilot Studio or full-stack deployments on Bedrock and Azure AI Foundry. Both clusters exist, both are real, but neither dominates, and a strong SWE with a focused ramp-up can step into either with surprisingly little friction.
The numbers, put simply, say this: today's AI Engineer is usually a software engineer building AI-powered products, not a researcher training models.
A Center of Gravity, Not a Takeover
The honest read on the market is that AI engineering is not being won by SWEs in any adversarial sense. It is being absorbed into Software Engineering, in the same way that web development absorbed graphic designers' workflows two decades ago and DevOps absorbed sysadmin work one decade ago. The MLE-flavored and Ops-flavored AI Engineers still exist and still matter, they sit at the boundaries where the SWE generalist needs a specialist.
But if you are a hiring manager trying to staff an AI initiative right now, the implication is concrete: you most likely need a strong software engineer who has shipped production systems with LLM APIs, who can reason about evaluation and cost, and who treats AI as a component in a larger system rather than the system itself.
And if you are a Software Engineer wondering whether you "have what it takes" to become an AI Engineer, the market has already answered. You do. The substrate is ready. The remaining work is the work you already know how to do: design clean systems, measure what matters, and ship things that don't break on Monday morning.
The AI Engineer of today wears a hoodie that says SWE on the front.


