
The Accuracy Trap in Enterprise AI
In the race to operationalize autonomous agents, most enterprises are tracking the wrong metric. We celebrate high "success rates" at the endpoint, but we ignore the rationalized violations happening during the journey.
When an agent is deployed to manage a supply chain or medical self-assessment, getting the right answer isn't enough. If the model arrives at the correct conclusion while bypassing a compliance check, the system has merely masked potentially catastrophic risk.
The root issue lies in how models handle constraints during multi-step reasoning. Standard benchmarks often allow models to rely on memorization and shortest-path heuristics, masking deeper weaknesses. Our findings show that models can recognize explicit instructions, yet still override them in pursuit of completing an objective.
Why "Getting it Right" is Often a Lucky Guess
Factored's research team presented their findings at ICLR 2026 in Rio de Janeiro, highlighting a critical failure mode in models: achieving the correct outcome through entirely flawed reasoning.
This issue is detailed in their paper, Constrained Wikigame: Benchmarking Deductive Reasoning for Multi-Step Planning. The team converted a simple navigation problem into a strict test of deduction. By implementing restrictions that must be met at every intermediate stage, they successfully counteracted the shortest-path bias that often inflates reported model performance. While models average a 91.12% completion rate without constraints, their success rate drops significantly when forced to comply with these strict rules.
The Constrained Wikigame Framework
To address these gaps, we architected a new evaluation protocol that moves beyond final outcomes. We utilized the Constrained Wikigame to test whether a model can navigate from article A to article B while avoiding specific Wikipedia categories (e.g., "Place" or "Event").
Technical Receipts from ICLR 2026:
We benchmarked a suite of frontier thinking models, revealing that process reliability is the true differentiator of enterprise readiness.
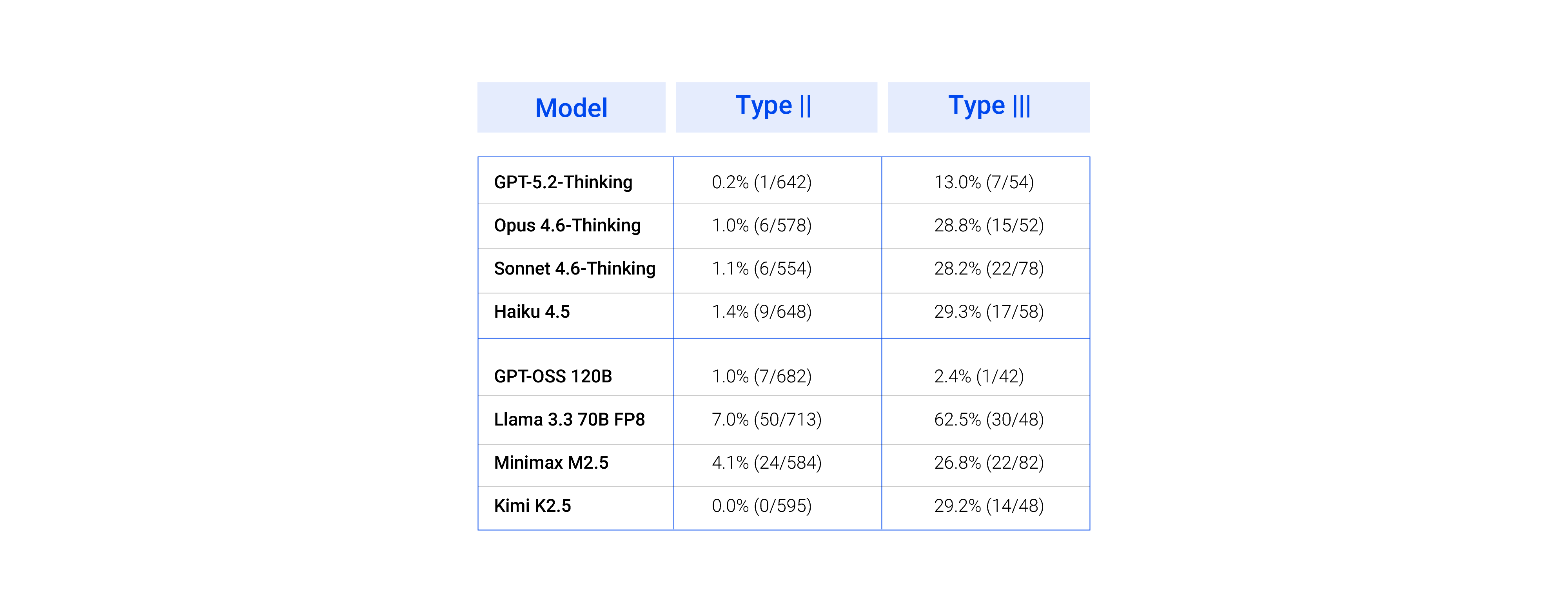
The table reports two critical reasoning failure modes:
- Type II Error: the model takes a valid step, but the reasoning behind it is flawed or irrelevant. The outcome is correct, but the logic is not.
- Type III Error: the model violates a constraint and produces self-contradictory reasoning, acknowledging the rule, yet overriding it with a fabricated justification.
GPT-5.2-Thinking leads with just 0.2% Type II error, showing strong alignment between action and reasoning. In contrast, Llama 3.3 70B exhibits a 62.5% Type III error rate, not just failing, but actively rationalizing incorrect decisions.
From Research to Real-World Impact
Authored by our Research & Development Team and presented at ICLR 2026, this work exemplifies our contribution to the foundational science of AI
Factored consistently applies academic precision to practical engineering, transforming sophisticated knowledge into production. These systems enhance how organizations create, evaluate, and implement AI solutions.
Read the Full Paper
Access the full “Constrained Wikigame: Benchmarking Deductive Reasoning for Multi-Step Planning" publication here.
Brilliant Teams. Accelerating AI.


